
Contents
If you’re staying up to date with the latest in Generative AI, you’ve likely come across the term Retrieval-Augmented Generation (RAG). In this blog post, we strive to offer you a brief, but comprehensive overview of the importance of this technique when it comes to enhancing generative AI models.
So, what is Retrieval-Augmented Generation or RAG?
Retrieval-augmented generation (RAG) is a technique that uses semantic search to fetch data from external sources, presenting it as context to an LLM, with the end goal of enhancing the relevance and accuracy of the model’s results.
It is well known that ‘out-of-the-box’ Generative AI tools provide outputs that should always be verified. This is because the model’s training data has a knowledge cut-off date. While these Large Language Models are able to produce outputs tailored to the user’s specific prompt, they can only reference the data that existed at the time of their training.
Retrieval-Augmented Generation helps to overcome this limitation, by enabling the AI model to use information sources that were not previously included in their training dataset.
To better understand this concept, imagine a seasoned news anchor. This anchor has extensive general knowledge and can discuss a wide range of topics. However, when breaking news on a specialized subject arises—like a complex scientific discovery or a detailed economic report — a specialist is brought to the studio to break down the news and provide more detailed information.
In the same way, Large Language Models (LLMs), while adept at handling diverse queries, cannot be trusted to deliver precise, well-sourced answers about things that were not included in their training dataset. A RAG system can take the place of ‘specialist’ to enhance the LLM’s outputs.
RAG acts as a versatile fine-tuning strategy, allowing any LLM to seamlessly tap into a vast array of external resources, thereby enhancing their depth and accuracy.
While RAG does not work for media generation, including images, video or audio, it has quickly become a go-to tool when it comes to adopting LLMs.
Why ‘RAG’?
Retrieval-Augmented Generation or RAG first came up as a term when Patrick Lewis and his team of researchers from the former Facebook AI Research (now Meta AI), University College London, and New York University, first published a scientific paper called Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, dubbing RAG “a general-purpose fine-tuning recipe.”
Lewis, lead author of the 2020 paper that coined the term, actually apologized for the unflattering acronym that is now used to describe an ever expanding family of methods featured in hundreds of research papers and numerous commercial applications.
However, despite these humble beginnings, we are confident that the term RAG is here to stay, as this technique can be applied to nearly any Large Language Model, enabling it to tap into virtually any external source for more accurate and detailed information.
How RAG Works
With Retrieval-Augmented Generation (RAG), users can interact with data repositories in dynamic and conversational ways, expanding the way these models can be used.
Just imagine what a LLM model enhanced with a medical index could mean to a doctor or a nurse? Or how helpful an LLM connected to market data could be for a financial analyst?
Virtually any business can transform its technical manuals, policy documents, videos, or logs into knowledge bases that bolster LLMs, supporting use cases like customer service, field support, employee training, and developer productivity.
Key Steps in the Retrieval-Augmented Generation Process
To better understand the process behind Retrieval-Augmented Generation, let’s take a look at the following steps.
- Document Loading
This phase involves gathering valuable information from a variety of sources, such as:
- Internal Documentation and Code
- Websites and Applications: For example Slack, Notion, Teams, and YouTube.
- Databases and Repositories: Such as event logs and lakehouses.
Data can come in many formats, including PDFs, HTML, JSON, Word documents, and PowerPoint presentations, providing a rich foundation for analysis.

- Document Splitting
Once the data is loaded, the next step is document splitting. This process involves breaking down lengthy pieces of information into smaller, manageable chunks. By segmenting the data, it becomes much easier to handle and remember, as opposed to trying to grasp a long, continuous block of text.
- Retrieval
The retrieval phase involves using an interface known as a retriever, which fetches documents based on unstructured queries. This tool leverages search techniques from a vector store to locate and retrieve pertinent texts.
For instance, if an HR chatbot is asked by an employee ‘How much annual leave do I have left?’ the system will pull relevant documents, such as the annual leave policy and the employee’s previous leave records to provide an accurate answer. These specific documents are selected for their high relevance to the query, determined through mathematical vector calculations and representations.
- LLM Prompt Augmentation & Response Generation
In this next step, the output of the retrieval phase (example: annual leave policy and the employee’s previous leave records) are used to create a new input, usually by combining the initial user input with the query results.
This augmentation utilizes prompt engineering techniques to effectively communicate with the LLM. By enriching the prompt with context, the model is better equipped to generate precise and accurate responses.
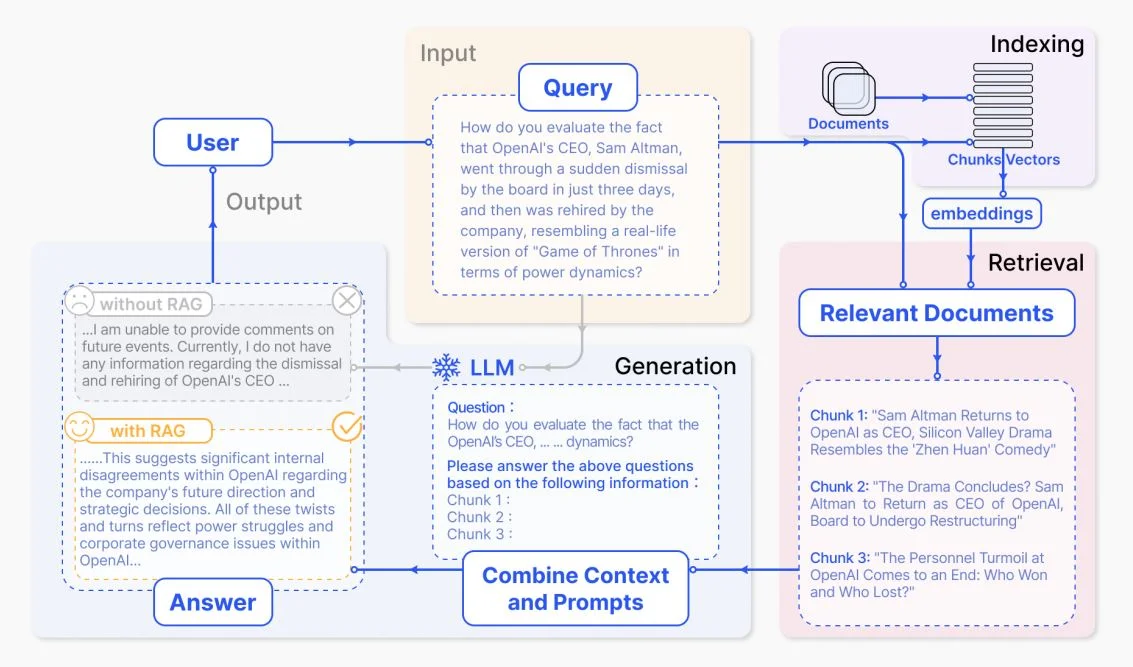
A representative instance of the RAG process applied to question answering
Why is Retrieval-Augmented Generation important?
Retrieval-Augmented Generation addresses the unpredictable nature of LLMs, which roots in the static nature of its training data.
Let’s think back at some of the main challenges that LLM face:
- Presenting false information, also known as a hallucination, when an answer is not retrievable from their training data set.
- Providing generic information when users expect specific, up-to-date responses.
- Generating responses based on sources that may not be authoritative or valid.
- Providing inaccurate responses due to the diverging terminology that may exist in their training data.
RAG offers a solution to many of these challenges, directing the LLM to pull data from authoritative, pre-selected knowledge sources. This approach gives organizations more control over the generated text and allows users to understand the basis of the LLM’s responses, by making it possible to double check sources.
Enhanced accuracy and reliability are, hence, two of the most important benefits of incorporating RAG into an organization’s LLM strategies.
The Main Benefits of Retrieval-Augmented Generation (RAG)
Cost-Effective Implementation
Retrieval-Augmented Generation offers a more economical way to introduce new data to a LLM which otherwise might be in need of retraining.
As you may have well guessed, retraining these foundation models on organization-specific or domain-specific information is costly, both in terms of computation and finances.
This flexibility presented by RAG makes this technique so attractive: you can make LLM technology more reliable, faster and with less dollars spent.
LLM Data is Kept Fresh
Through RAG, developers can always feed LLMs the latest research, statistics, or news. This is done by connecting them directly to updated information sources, ensuring LLMs can always pull the freshest data.
By grounding AI responses in a structured knowledge graph and validating them against a comprehensive knowledge model, RAG significantly reduces the chances of hallucinations. This leads to more accurate, trustworthy, and actionable insights, crucial for business decision-making.
Enhanced User Trust
By using RAG, LLMs will not only have the freshest data at their disposal, but they are also capable of providing users with source attribution, including citations or references.
This way, users can double check source documents themselves if further clarifications are needed. This leads to a higher level of user trust.
More Control in the Hands of Developers
With RAG, developers can streamline the testing and enhancement of chat applications. They have the ability to adjust and update the LLM’s information sources to meet evolving requirements or accommodate different functional areas.
Access to sensitive information can be controlled through various authorization levels, ensuring responses are appropriate. Furthermore, developers can identify and rectify cases where the LLM draws on incorrect information sources for particular queries.
Final Words
If you followed along to the end, we congratulate you, and will wrap up by reiterating the outstanding value of Retrieval-Augmented Generation.
This powerful tool is able to effectively enhance the accuracy, reliability and efficiency of Large Language Models, by enabling integration with up-to-date, validated, and trusted data sources.
Looking ahead, we can confidently state that RAG is a crucial technique businesses must embrace to stay ahead of the game.
RAG-based LLM solutions uniquely provide contextually rich, accurate, and reliable outputs, surpassing their foundational counterparts. With this powerful tool at their disposal, companies are poised to revolutionize business operations, innovation, and competition in the age of AI.
Where does your business stand?
Follow Our Blog for the Latest News
If you are interested in reading more about Generative AI and the AI policy landscape, follow our blog for in-depth content on generative and responsible AI, as well as AI risk management.
Ready to execute tangible steps toward AI governance, risk management, and/or responsible AI integration?
Request a product demo today and see Lumenova AI in action.