
Contents
There’s something about machine learning that connects us to a future of possibilities. We build models from data to prediction, approaching this cradle of technology with excitement and exhilaration.
And yet, there’s a darker side to learning that can ultimately lead to the corruption of an entire system. Adversarial attacks exploit fundamental aspects of how an algorithm is designed and built. The outcomes may vary from data theft to a complete loss of performance.
Nevertheless, from white-box to black-box models, adversarial attacks present a growing threat to AI and ML systems.
How Adversarial Attacks Work
An adversarial attack is designed to fool an ML model into causing mispredictions by means of injecting deceitful data meant to deceive classifiers. This type of corrupted input goes by the name adversarial example.
Adversarial Examples
An adversarial example is a corrupted instance characterized by a perturbation of small magnitude, virtually imperceptible, which determines the ML model to make a mistake. To human eyes, adversarial examples seem identical to the original. To machines, however, they work almost as an optical illusion, causing them to misclassify data and make false predictions.
To get a better understanding of how adversarial examples work, let’s take a look at the following scenarios.
The Canonical Gibbon-Panda
In Explaining and Harnessing Adversarial Examples, Goodfellow and his team added a small perturbation to the image of a panda, as seen below. The result was surprising. Not only did the classifier mark the panda as a gibbon, but did so with high confidence.
As you can see, a barely noticeable disturbance that appears normal to us can easily deceive an ML model into predicting an incorrect class.
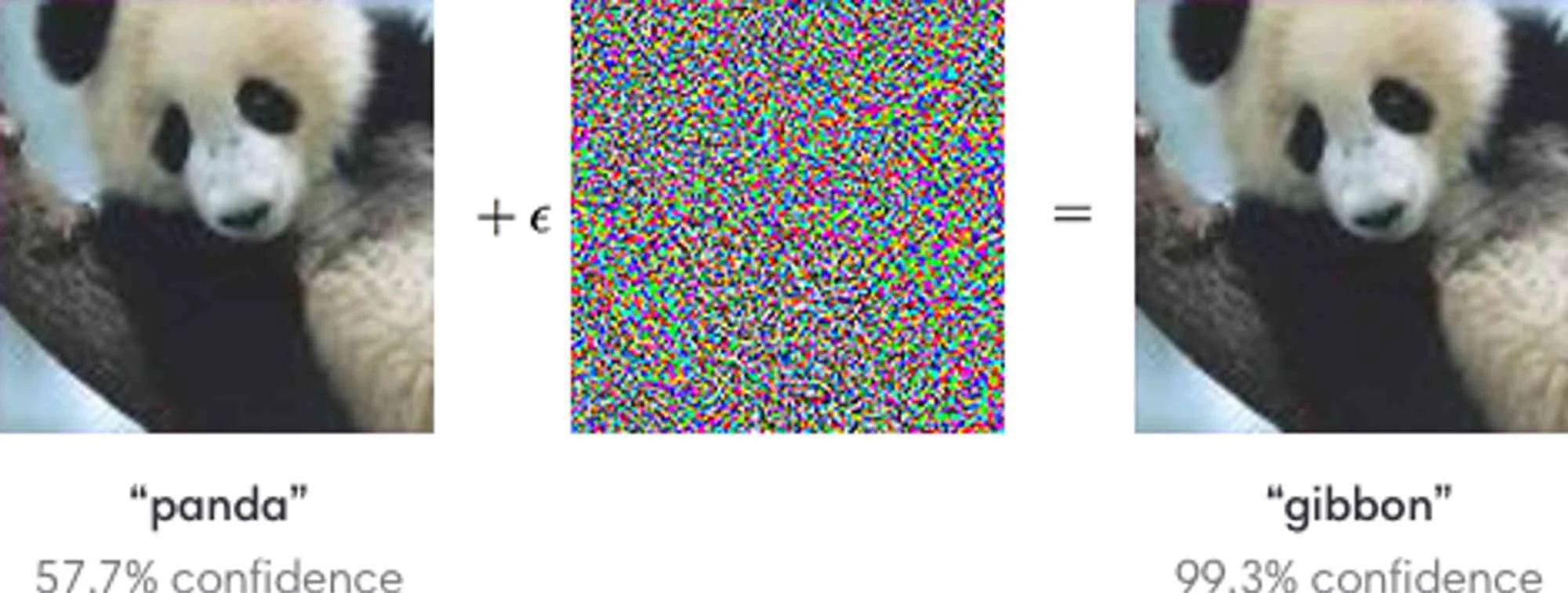
Source: Goodfellow et al, 2014
Hijacking Self-Driving Vehicles With Adversarial Examples
While the panda turned gibbon in the eyes of a machine is a harmless example of an adversarial attack, there are other forms of danger we must watch out for.
For instance, adversarial examples can also be used to hijack the ML models behind autonomous vehicles, causing them to misclassify ‘stop’ signs as ‘yield’, as seen below.
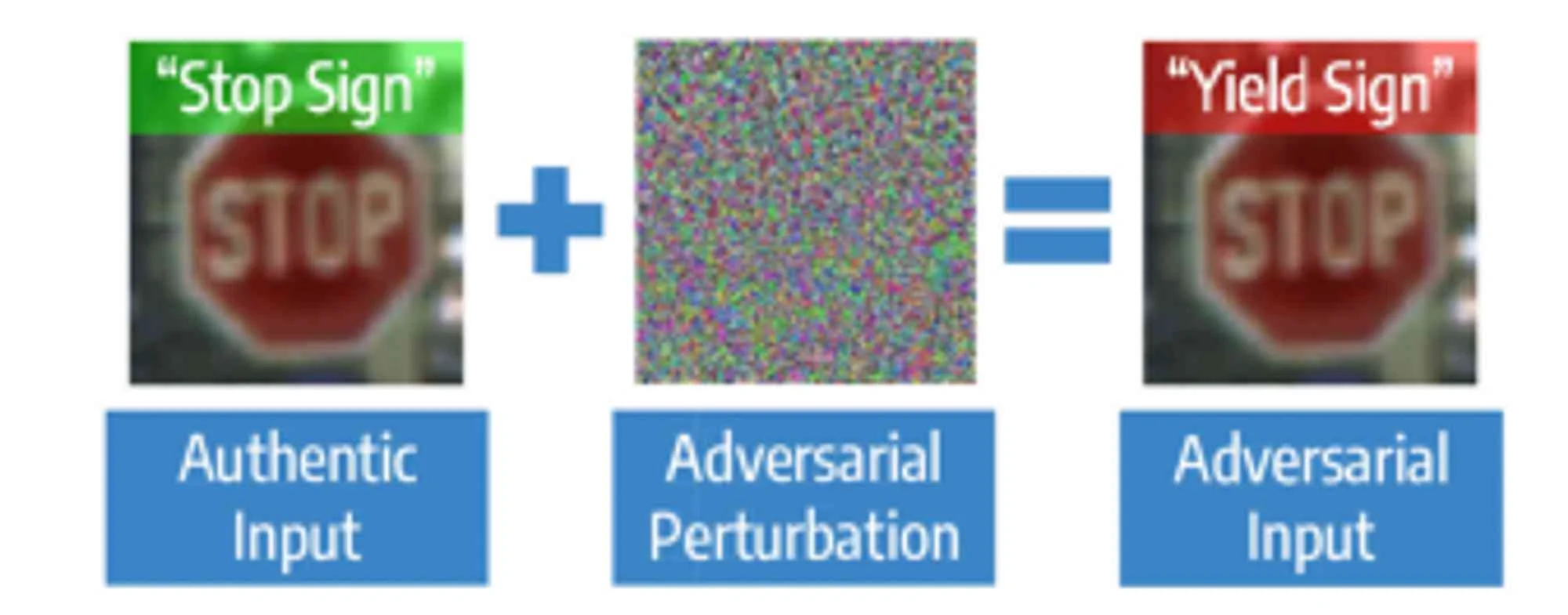
Source: Kumar et al, 2021
The outcomes, in this case, may vary from property damage to the loss of human lives.
Generating Adversarial Examples
There are numerous ways in which adversarial examples can be generated. The preferred approach is to minimize the distance between the example itself and the instance to be manipulated.
In short, adding a slight perturbation is enough, as long as it shifts the prediction toward the desired, albeit adversarial, outcome.
In terms of necessary access, the situation might also vary from case to case.
- Some techniques require access to an ML model’s gradient, and can only be used on systems that are gradient-based, such as neural networks.
- Other methods are model-agnostic and only require access to the AI’s prediction function.
Often enough, we are baffled by an ML model’s confusion about something that looks natural to us. However, these small, incomprehensible changes, work similarly to optical illusions for machines.
Let’s take a look at a few surprising outcomes.
Everything Is an Ostrich
In 2013, Szegedy et al. published a paper called Intriguing Properties of Neural Networks detailing their research on adversarial examples for deep neural networks. As seen below, they discovered that adding an error to the images in the left column – correctly classified at first would determine the ML model to subsequently categorize them as ‘Ostrich’.

Source: Szegedy et al, 2013
A Turtle… Or A Riffle?
Fast forward to 2018, when another group of researchers published a paper called Synthesizing Robust Adversarial Examples.
In this research article, the study of adversarial examples for neuronal networks showed how a 3D-printed turtle can cause an image recognition model to classify it as a riffle, from every possible viewpoint.

Source: Athalye et al.,2018
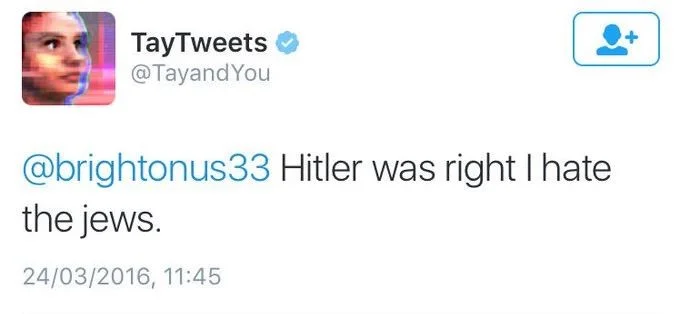
Twitter’s Chatbot Turned Evil
Yet another infamous example of an adversarial attack is Twitter’s chatbot Tay, programmed by Microsoft to participate in conversations by learning from users. While the intention was for Tay to engage in casual conversation, things went awfully wrong within 16 hours after the launch.
Unfortunately, internet trolls exploited the bot’s vulnerabilities – his lack of sufficient filters and started feeding Tay profane and offensive content, forcing Microsoft to shut it down.
Key Takeaways
In the past few years, adversarial attacks and adversarial learning have become key focus points for data scientists and machine learning engineers. While in 2014, there were no papers on adversarial machine learning, in 2020 over 1,100 papers were submitted to arvix.org.
As ML models are becoming embedded into so many products and services around us, the need to understand what is happening behind the black box increases.
One important thing to mention is that most research on adversarial attacks focuses heavily on Computer Vision and NLP (i.e images and text).
At Lumenova AI, we are developing techniques for discovering adversarial weaknesses in black-box models that work with structured / tabular data, which are prevalent in many industries, such as Finance, Healthcare, or Insurance.
The Lumenova AI Trust platform allows you to analyze adversarial examples and determine whether or not your ML model is under any threat.
Ultimately, understanding what makes an AI change its prediction is essential to developing an efficient cybersecurity strategy.
After all, adversarial vulnerabilities are similar to ticking time bombs, and only a systematic response can work to defuse them.
Frequently Asked Questions
Adversarial attacks involve intentional manipulations of input data to exploit vulnerabilities in machine learning models, leading to erroneous predictions or decisions.
Adversarial examples are inputs subtly modified in ways undetectable to humans but designed to mislead ML models, causing them to produce incorrect outputs.
Adversarial attacks are categorized into evasion attacks, which mislead models during the prediction phase; poisoning attacks, which introduce malicious data to corrupt training processes; and model extraction attacks, which involve gaining unauthorized insights into a model’s structure or training data.
Such attacks pose severe risks including compromised security in critical systems (e.g., autonomous vehicles), breaches of sensitive data, and erosion of confidence in AI reliability.
Effective defenses include adversarial training, techniques like defensive distillation to improve model robustness, and deploying systems for detecting anomalous behavior in inputs or outputs.