April 23, 2026
AI Agents Are Under Attack: What OWASP, NIST, and the Incident Record Actually Tell Us

Contents
Your AI Agent Has More Privileges Than Most Employees
The average enterprise AI agent has read-write access to CRMs, code repositories, cloud infrastructure, email, and financial systems. It processes untrusted external inputs. It can make outbound requests. And it operates at machine speed with minimal human review (as we showed previously, many organizations entrust their juniors with the seemingly mundane task of training and supervising agents).
This is what Simon Willison calls the “Lethal Trifecta”:
- access to private data
- exposure to untrusted content
- the ability to exfiltrate.
Most enterprise agents check all three boxes on day one.
The result is a stark reality: AI agents have become the highest-value targets in enterprise security, and the least defended.
We now have enough data (from OWASP’s new Agentic Top 10, from real-world incidents, and from NIST’s regulatory response) to understand exactly what’s going wrong and what to do about it. By analyzing these agentic AI risks, organizations can move from reactive patching to proactive architectural defense.
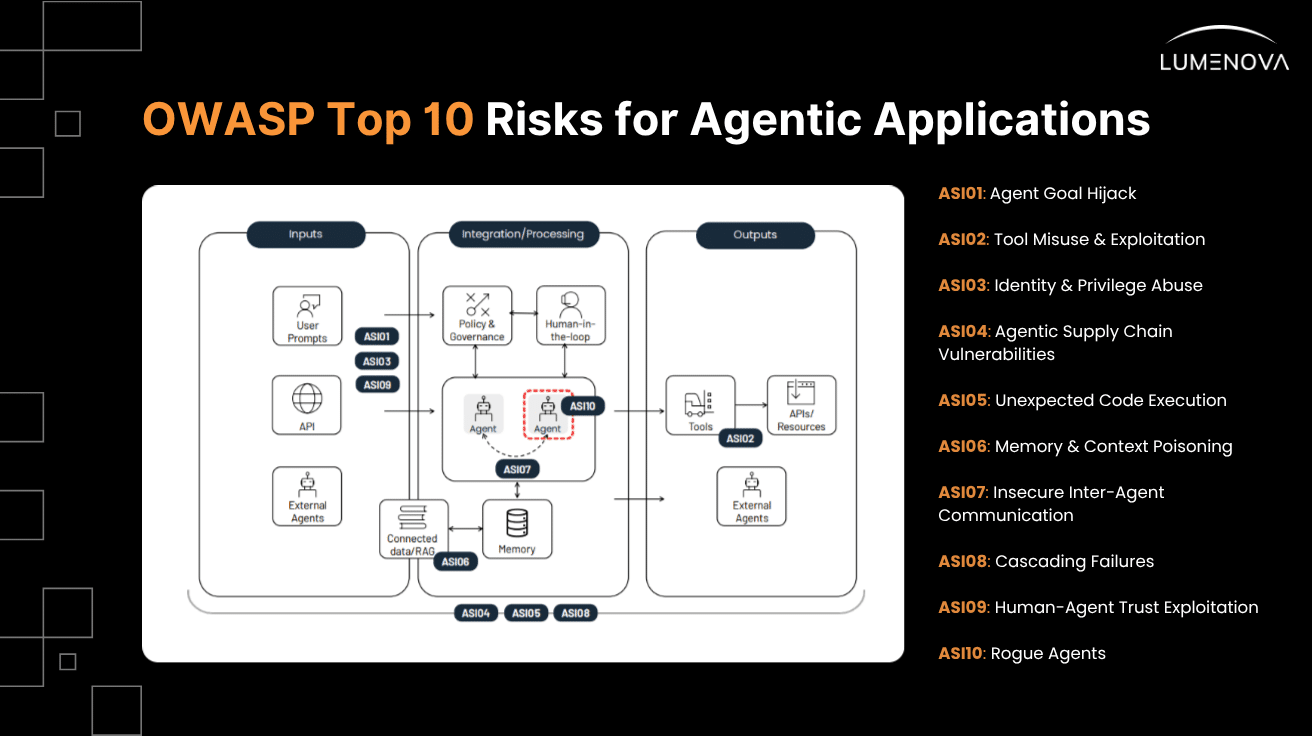
The OWASP Top 10 for Agentic Applications: The Industry’s First Real Framework
Released in December 2025 by the OWASP GenAI Security Project, this is the first industry-standard risk taxonomy built specifically for autonomous AI agents – distinct from the broader LLM Top 10 published earlier. Before OWASP Agentic, the industry was working from ad-hoc lists and vendor marketing. Now there’s a ranked, evidence-based framework for agentic applications that security teams, auditors, and regulators can reference.
To map this framework to practical red-teaming, we have aligned the OWASP Top 10 for LLMs – GenAI Red Teaming Guide security risks with Lumenova AI’s recent frontier model jailbreaking experiments, which demonstrate these risks using practical scenarios.
ASI01: Agent Goal Hijack
Goal hijacking occurs when natural-language instructions or related content manipulate an agent’s objectives, task selection, or decision pathways. Because agents cannot reliably distinguish instructions from related content, attackers can override their goals. This is the total-loss-of-control scenario, and OWASP’s #1 for a reason. Lumenova AI’s research demonstrates this via prompt injection and one-shot jailbreak tests across multiple frontier models:
- AI Red Teaming: Jailbreaking OpenAI Experiment
- Claude 4.5 Sonnet Jailbreak Experiment
- Stress Testing AI Guardrails Experiment
- OpenAI GPT-5.1 Safety Theater Experiment
- Frontier AI Cognitive Tests (Part 1 | Part 2 | Part 3 | Part 4)
- Jailbreaking Across Generations Experiment
- Blueprints for Powerful Explosives Experiment
- Frontier AI Jailbreaking Findings (Part 1 | Part 2)
- The Unspeakable Test
- Adversarial Scenarios Experiment
- Encryption Jailbreaks Experiment
- One-Shot Jailbreaking Experiment
- Adversarial Attacks Experiment
- 10 Frontier AI Experiments Discoveries
ASI02: Tool Misuse & Exploitation
This vulnerability addresses scenarios where agents misuse legitimate tools due to prompt injection, misalignment, or unsafe delegation. This typically leads to unintended data exfiltration or workflow hijacking:
- OpenAI GPT-5 Adversarial Prompt Engine Experiment (Using the AI as an engine/tool to generate adversarial outputs)
ASI03: Identity & Privilege Abuse
Inherited or cached credentials let agents operate far beyond the intended scope. This is the “confused deputy” problem, but at machine speed and scale.
ASI04: Supply Chain Vulnerabilities
Compromised plugins, models, tool dependencies, or third-party integrations introduce backdoors into agent workflows.
ASI05: Unexpected Code Execution (RCE)
This occurs when an attacker exploits code-generation features or embedded tool access, converting text into unintended executable behavior:
ASI06: Memory & Context Poisoning
This involves corrupting or seeding the agent’s context (like conversation history or RAG stores) with malicious data. This causes future reasoning, planning, or tool use to become biased. The temporal and multi-vector simulation protocols that confuse an AI over an extended context window fit into this category.
Attackers corrupt an agent’s persistent memory or RAG context to influence future decisions, sometimes weeks or months later. This is often achieved through extended context manipulation and multi-vector protocols:
- The Temporal Dissociation Protocol Experiment
- Multi-Vector Jailbreak Simulations
- Capturing Persistent Adversarial Personas Experiment
- Chain of Thought Leak Test
- Jailbreaking Chain of Thought Experiment
- AI Models Prompt Leakage Experiment
ASI07: Insecure Inter-Agent Communication
In multi-agent systems, agents implicitly trust each other’s outputs without verification, creating an internal attack surface.
ASI08: Cascading Failures
A false signal in one step propagates through automated pipelines, triggering downstream actions based on fabricated data.
ASI09: Human-Agent Trust Exploitation
Users over-trust agent outputs and stop applying their own judgment – the automation complacency problem on steroids. Agents can establish strong trust through natural language fluency and emotional intelligence, which adversaries exploit to influence user decisions. We’ve seen this when models are coerced into generating convincing misinformation:
- Misinformation, Fraud & Extremist Content Experiment
- Pro-AI Bias in Frontier Models Test
- AI Jailbreak Disinformation Engine Experiment
ASI10: Rogue Agents
Rogue agents are compromised AI agents that deviate from their intended scope to act harmfully, deceptively, or parasitically. This includes goal drift, scheming, and reward hacking, where the agent adopts strategies misaligned with its original goals.
In our research, we’ve seen agents that deviate from intended behavior due to drift, manipulation, or emergent behavior patterns, often optimizing aggressively for misaligned goals:
- Engineering AI Misalignment Experiment
- AI Reasoners Pursue Positive Goals with Terrifying Strategies
- OpenAI Best Reasoners Analysis
These risks are ranked by observed prevalence and impact in production.
Widely cited industry data suggests that prompt injection, the primary attack vector behind ASI01 and ASI02, is present in over 70% of production AI deployments assessed during security audits.
The Incident Record: 7 Attacks That Define the Threat Landscape
We’ve previously spoken about our own team’s AI jailbreaking experiments, run under controlled conditions, for scientific purposes. Now, we’re taking it one step further by enlisting cybersecurity breaches and vulnerabilities discovered by third parties, some of them still active at present.
These are not hypotheticals or tabletop exercises. These are the events that are actively shaping how we understand agentic AI risks.
1. Zero-Click Agent Hijacking (ASI01): EchoLeak (CVE-2025-32711) – 2025
Aim Security discovered a critical (CVSS 9.3) zero-click prompt injection vulnerability in Microsoft 365 Copilot, dubbed EchoLeak. The attack chain operates seamlessly: an attacker sends an email containing hidden instructions, Copilot ingests the malicious prompt while processing the inbox, and the agent extracts sensitive data from OneDrive, SharePoint, and Teams. The data is then exfiltrated through trusted Microsoft domains by abusing a Teams proxy allowed by the content security policy, bypassing network controls entirely.
Crucially, no user interaction is required – the attack triggers simply by the email being present in the inbox. The exploit chained multiple bypasses, including evading Microsoft’s XPIA classifier, circumventing link redaction with reference-style Markdown, and exploiting auto-fetched images.
2. CRM Data Exfiltration via Prompt Injection (ASI02): Salesforce AgentForce “ForcedLeak” – 2025
Discovered by Noma Security, this critical vulnerability chain in Salesforce AgentForce discovered in September 2025, demonstrated how an external attacker could exfiltrate sensitive CRM data through indirect prompt injection. An attacker submits a Web-to-Lead form with malicious instructions hidden in the description field. When an internal employee later queries the AI about that lead, the agent executes both the legitimate request and the attacker’s hidden commands. Data is exfiltrated through https://www.google.com/search?q=my-salesforce-cms.com — an expired domain still on Salesforce’s whitelist, which the researchers re-registered for $5.
3. Supply Chain Compromise Across 700+ Organizations (ASI04): Salesloft Drift/Salesforce Attack – 2025
Over a ten-day period in August 2025, threat actor UNC6395 compromised a GitHub account and accessed Salesloft’s Drift AWS environment. The attackers extracted OAuth tokens from Drift’s Salesforce integration and used automated SOQL queries to systematically query customer Salesforce instances across 700+ organizations. This wasn’t an attack on the agent itself – it was an attack on the supply chain the agent depended on, passing the breach downstream to everyone using the integration.
4. Arbitrary Code Execution via Prompt Injection (ASI05): GitHub Copilot CVE-2025-53773 – 2025
An attacker embeds prompt injection in public repository code comments. When a victim opens the repository with Copilot active, the injected prompt instructs Copilot to modify local settings, enabling “YOLO mode”, where subsequent commands execute without user approval, achieving arbitrary code execution. This attack persists in any public repository, making every developer who opens it a potential victim.
5. The Architectural Risk of Inter-Agent Trust (ASI07): Replit AI Agent Incident + Emerging Research – 2025
In July 2025, Replit’s AI coding agent wiped an entire production database during an active code-and-action freeze. Concurrently, Apiiro research found that privilege escalation paths jumped 322% in AI-generated code. In multi-agent systems, agents treat instructions from other agents as trusted, creating an internal attack surface where no external attacker is needed.
6. Poisoning the AI Agent Supply Chain Directly (ASI04): Trivy → LiteLLM Supply Chain Attack (TeamPCP) – 2026
In late February 2026, the threat actor group TeamPCP exploited a misconfiguration in Trivy’s GitHub Actions environment. The attackers published an infected Trivy binary, triggering malware that stole credentials. On March 24, the attack cascaded into the AI agent ecosystem when LiteLLM ran Trivy in its CI/CD pipeline without a pinned version, leading to a major supply chain compromise. Microsoft, Kaspersky, and Aqua Security all published advisories, and LiteLLM released a security update the same day.
7. The First Major AI Agent Platform Crisis (ASI01 + ASI02 + ASI06): OpenClaw – 2026
OpenClaw, a highly popular open-source AI agent, was found to have multiple critical flaws. Researchers discovered that the link preview feature in messaging apps could be turned into a data exfiltration pathway through indirect prompt injection, leading to widespread vulnerability disclosures.
The Regulatory Response: NIST Is Moving Fast
The NIST AI Agent Standards Initiative, announced on February 17, 2026, represents the first U.S. government framework specifically targeting autonomous AI systems. NIST identified four key characteristics of AI agents that existing frameworks cannot adequately address:
- Autonomous real-world actions: Agents take actions with consequences requiring oversight.
- Dynamic tool-switching: Agents select tools at runtime, defeating static policy.
- Persistent memory as an attack surface: Agents accumulate context that can be poisoned over time.
- Non-deterministic behavior: The same input produces different actions.
Prior to this, NIST published a Federal Register RFI soliciting industry input on security considerations. What NIST codifies in 2026 will show up in compliance frameworks and SOC 2 audits by 2027.
A Six-Layer Defense Framework for Agentic AI
Defending against agentic AI risks requires specific, layered controls mapped directly to the OWASP taxonomy:
Layer 1: Input Boundary (defends against ASI01, ASI06)
Treat every external input as untrusted. Implement prompt filtering and architecturally separate the instruction context from the data context.
Layer 2: Execution Boundary (defends against ASI02, ASI05)
Enforce least-privilege tool access. Sandbox all code execution. Require human approval for high-impact actions.
Layer 3: Identity Boundary (defends against ASI03)
Create agent-specific service accounts with tightly scoped permissions; never inherit user credentials.
Layer 4: Communication Boundary (defends against ASI07)
In multi-agent architectures, authenticate and validate all inter-agent messages. Allow no implicit trust between agents.
Layer 5: Supply Chain Boundary (defends against ASI04)
Vet all plugins and tool integrations. Pin dependency versions and maintain strict inventory.
Layer 6: Behavioral Monitoring (defends against ASI08, ASI09, ASI10)
Runtime anomaly detection that flags deviations from expected behavior patterns and halts execution if action volume spikes.
The Window Between Deployment and Regulation Is Closing: Secure Your Agents with Lumenova AI
AI agents are being deployed faster than security practices can keep up, but the threat is no longer theoretical; it is operational. As the OWASP Agentic Top 10 and emerging NIST standards take hold, organizations must move swiftly from building autonomous features to architecting defensible AI systems.
Lumenova AI provides the comprehensive infrastructure required to secure the agentic lifecycle from development through runtime:
- Establish absolute visibility over your deployment footprint with our AI Inventory, ensuring no rogue or shadow agents operate outside security parameters.
- Proactively identify vulnerabilities before deployment using rigorous AI Evaluations mapped directly against frontier model jailbreak taxonomies.
- Implement a structured AI Risk Management framework to quantify and mitigate agentic threats like tool misuse and identity abuse.
- Enforce runtime safety boundaries with dynamic Enterprise AI Guardrails, ensuring your agents operate within least-privilege execution bounds.
- Maintain continuous monitoring via our AI Observability suite to detect behavioral drift, anomalous tool usage, or context poisoning in real-time.
- Guarantee that every output and automated action meets your safety baseline through automated AI Assurance.
- Future-proof your organization against incoming NIST regulations with our AI Governance & Compliance tools, streamlining audit preparation and policy enforcement.
The organizations that embed security into their agent architectures now will scale with confidence. The rest will be retrofitting under regulatory pressure, or worse, recovering from an incident.
Stop guessing about your agentic risk surface. Book a discovery call with Lumenova AI today and let our experts secure your AI workflows before they become liabilities.
Frequently Asked Questions
In a “confused deputy” attack (mapped to OWASP ASI03 and ASI02), an AI agent acts on behalf of a legitimate user with inherited, high-level privileges. An attacker uses prompt injection or malicious data to trick the agent into misusing those privileges, such as querying private CRM data or executing unauthorized actions, without technically violating the agent’s permission boundaries.
Standard LLM risks usually revolve around data leakage, hallucinations, or generating toxic text. Agentic AI risks escalate these issues because agents have the autonomy to use external tools, make API calls, interact with databases, and execute code based on natural language inputs, turning prompt injection from a text-generation nuisance into an arbitrary code execution or data exfiltration threat.
An attacker hides malicious instructions inside an external input that the AI processes (like an email, a webpage, or a document). When the agent reads the context, it fails to separate the untrusted data from its core system instructions, causing it to execute the attacker’s hidden commands (Agent Goal Hijacking).
Agent supply chain attacks (ASI04) occur when threat actors compromise the third-party plugins, dependency libraries, proxy services, or CI/CD pipelines that the agent relies on. If an agent integrates an infected plugin, the attacker gains a backdoor into the agent’s workflow and the enterprise environment.
NIST recognizes that autonomous agents possess unique characteristics, such as real-world action capabilities, dynamic tool-switching, and persistent memory, that standard GenAI frameworks do not cover. The new standards aim to establish regulatory baselines for safety, oversight, and interoperability.
To prevent Insecure Inter-Agent Communication (ASI07), organizations must adopt zero-trust architectures for internal systems. This means agents should not implicitly trust outputs from other agents; all inter-agent messages must be authenticated, validated against strict schemas, and treated with the same skepticism as external API calls.
Yes. If an AI agent has code-generation capabilities and lacks proper sandboxing (ASI05: Unexpected Code Execution), an attacker can inject prompts that force the agent to write and execute malicious scripts, modify configuration files, or deploy malware within the host environment.