August 14, 2025
AI Security Solutions: Your First Line of Defense Against AI Model Adversarial Attacks and Threats

Contents
In our physical world, we rely on security squads and police forces working tirelessly, often unseen, to maintain law and order. They are the guardians of our public and private safety. In the burgeoning world of cyberlife, a similar need exists for robust AI security solutions: powerful structures to enforce regulations, prevent malicious activity, and mitigate harm. These digital guardians work silently (just as attackers do!), but their role is critical in reliably keeping us safe from the darker side of AI’s potential.
This brings us to the core vulnerability of AI: its susceptibility to deception. Just as optical illusions can trick the human brain into seeing something that isn’t there, adversarial attacks can fool AI models. These are malicious attempts to trick, manipulate, or steal from AI systems by exploiting their underlying mathematical logic. An attacker can craft inputs that, while appearing normal to us, cause an AI to make a catastrophic error, like misidentifying a stop sign as a green light or approving a fraudulent transaction.
As organizations increasingly stake their futures on AI, understanding these threats is no longer optional. This blog post will break down the common types of AI attacks and explore the cutting-edge security solutions and multi-layered strategies designed to defend against them, ensuring that AI remains a tool for progress, not turning into a vector for chaos.
Overview
This article provides a comprehensive analysis of the critical field of AI security, exploring the landscape of threats targeting machine learning models and the advanced solutions designed to counter them. As AI systems become integral to modern business operations, understanding their unique vulnerabilities is paramount. We move from defining the problem of adversarial attacks to detailing a robust, multi-layered defense strategy, making the case that specialized AI security solutions are no longer optional but essential for any organization deploying AI.
We begin by defining common adversarial threats, including data poisoning, evasion attacks, and model extraction, explaining why traditional cybersecurity tools fall short in protecting against them. The core of the article then introduces the foundational principles of security applied to AI and outlines a multi-layered defense strategy. This includes securing the data foundation, hardening the model itself through techniques like adversarial training, and implementing real-time model monitoring and response systems. We also explore specific protection techniques and emerging trends like zero-trust AI architectures.
Ultimately, the post concludes that building a secure AI future requires a continuous, holistic approach. It summarizes the key defensive strategies and reinforces the idea that trust in AI can only be achieved by embedding security into every stage of its lifecycle. The piece serves as a guide for organizations to move from basic model deployment to safe, compliant, and transparent AI operations, urging them to adopt a proactive security posture.
Understanding AI Model Attacks and Adversarial Threats
Adversarial attacks can target any stage of the AI lifecycle, from the initial data collection to the final deployment. The “enemy” is sophisticated, aiming to undermine the integrity, confidentiality, and availability of AI systems.
Let’s explore the primary attack vectors.
Poisoning attacks (training time)
Think of this as contaminating the well from which the AI drinks. Attackers inject maliciously crafted data into the model’s training dataset. Because the AI learns from this corrupted information, it develops a “Trojan horse” – a hidden backdoor or bias. When the attacker later provides a specific trigger input, the model behaves exactly as they intended.
Example: Researchers demonstrated they could poison a dataset used to train a traffic sign classifier. By inserting a few images of stop signs with a small yellow sticker on them, they trained the model to classify any stop sign with that sticker as a “Speed Limit 80” sign. In a self-driving car, the consequences would be fatal.
Evasion attacks (inference time)
This is the most classic and widely discussed form of adversarial attack. It occurs after the model is fully trained and deployed. The attacker makes subtle, often mathematically precise, and human-imperceptible modifications to an input to fool the model into making an incorrect prediction.
Example: The canonical example involves image classifiers. A famous study showed that by adding a carefully calculated layer of “noise” to an image of a panda, an AI model that was 99% confident it was a panda suddenly became 99% confident it was a gibbon. The modified image looks identical to a human. This same technique could be used to fool facial recognition security systems or medical diagnostic AIs.
Model extraction & privacy attacks
These attacks are more insidious, focusing on theft rather than deception.
Model extraction (model theft)
Adversaries with access to a model’s API can repeatedly query it with different inputs and analyze the outputs. By doing so, they can reverse-engineer and create a functional copy of the proprietary model, stealing valuable intellectual property that may have cost millions to develop.
Privacy attacks (membership inference)
These attacks aim to determine whether a specific individual’s data was part of the model’s training set. For a healthcare model trained on sensitive patient records, a successful inference attack could constitute a massive data breach, revealing private medical information.
The consequences of these attacks are severe, ranging from direct financial losses and data breaches to catastrophic safety failures and irreparable reputational harm.
Why Traditional Security Measures Fall Short In the Realm of AI
Organizations might assume their existing cybersecurity arsenal is sufficient. However, traditional tools like firewalls, network security protocols, and anti-virus software are designed to protect infrastructure, not intelligence.
- Firewalls are gatekeepers for network traffic; they don’t analyze the content of a data packet to see if it’s an adversarial example.
- Anti-virus software looks for known malware signatures; it has no concept of the statistical perturbations that define an evasion attack.
- Intrusion detection systems monitor for unauthorized network access, not for legitimate-looking API calls designed to poison or steal a model.
AI systems are not static programs with fixed rules. They are dynamic, probabilistic systems whose decision boundaries are complex and often non-intuitive. Protecting them requires a new paradigm—one that understands the unique vulnerabilities of machine learning itself.
Core Principles of AI Security Solutions
Modern AI security is built on a foundation of proactive and adaptive principles designed to address the unique challenges of machine learning systems.
Defense-in-depth (DiD)
There is no single silver bullet. A robust security posture involves multiple layers of defense, from securing the initial data to monitoring the model in production.
Explainability (XAI)
Understanding why a model makes a certain prediction is crucial. If a model’s decision is uninterpretable, it’s nearly impossible to diagnose whether it’s been compromised or is behaving erratically.
Continuous monitoring
The threat landscape is always evolving. Security isn’t a one-time check; it’s a continuous process of monitoring model inputs, outputs, and behavior for signs of attack.
Robustness
This is the measure of a model’s resilience to adversarial perturbations. The goal is to build models that are inherently less sensitive to the small input changes that attackers exploit.
Risk assessment and governance
Before deploying any AI, organizations must assess its potential risks and establish clear governance policies. This includes understanding regulatory requirements (like the NIST AI RMF or the EU AI Act) and defining acceptable performance and security thresholds.
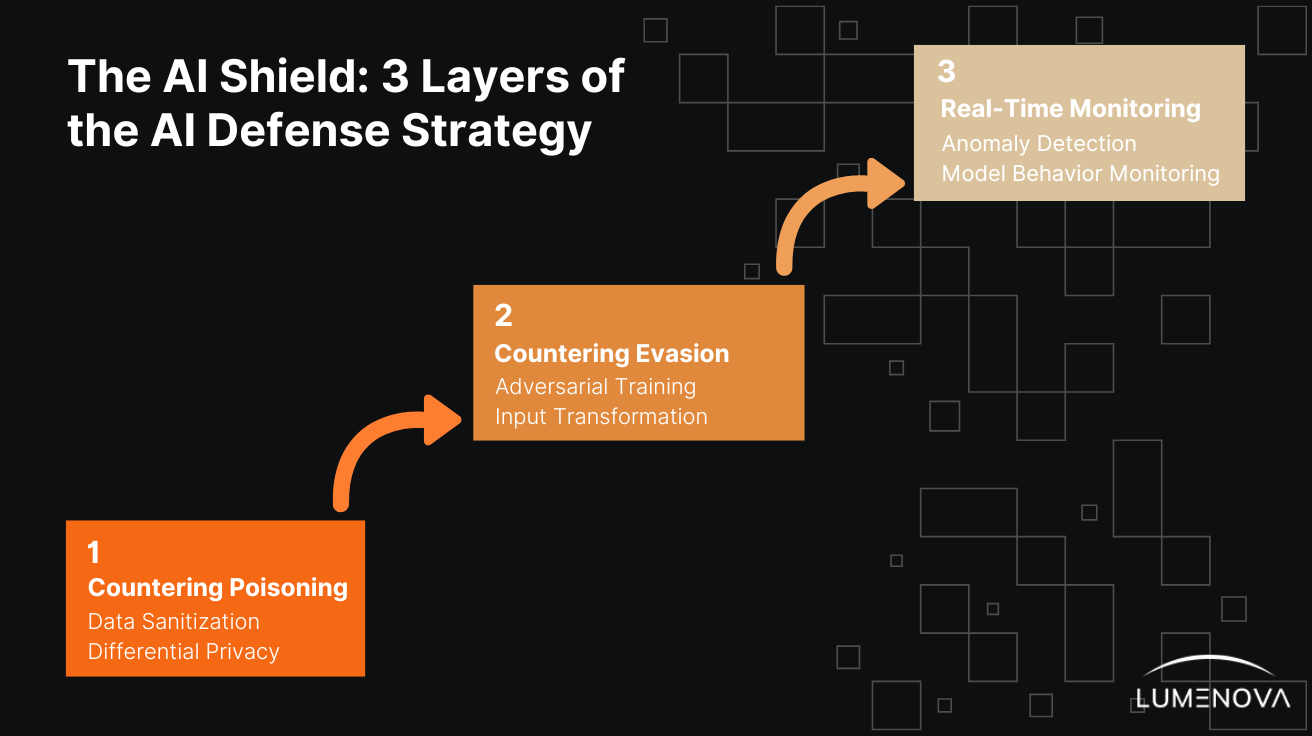
The AI Shield: A Multi-Layered Defense Strategy
Securing an AI model is somewhat like defending a medieval castle. You need strong walls, vigilant guards, and a secure supply line. This translates into a three-layered defense strategy.
Layer 1: Securing the foundation (countering poisoning)
This is about protecting your supply line: the data.
Data sanitization
Before any data is used for training, it must undergo a “purity test”. Security tools and MLOps pipelines can automatically scan datasets for statistical anomalies, outliers, and formatting inconsistencies that could indicate a poisoning attempt.
Differential privacy
This sophisticated technique acts like a “fog of war” for your data. By injecting a carefully calibrated amount of statistical noise into the dataset, it allows the model to learn broad patterns without memorizing specific data points. This makes it extremely difficult for an attacker to perform membership inference attacks and can help mitigate certain poisoning strategies.
Layer 2: Hardening the model (countering evasion)
This is about reinforcing the castle walls to make them resistant to attack.
Adversarial training
This is essentially an AI vaccine. The model is intentionally trained not just on clean data, but also on a curated set of adversarial examples. By learning to correctly identify these malicious inputs during training, it becomes far more robust against similar evasion attempts in the wild.
Input transformation
This is a pre-processing shield. Before an input is fed to the model, it is slightly altered – for example, by compressing the image, smoothing its pixels, or resizing it. These transformations can effectively “smudge” and destroy the attacker’s carefully crafted adversarial noise, neutralizing the threat.
Layer 3: Real-time monitoring & response (the security guard)
This is about having guards on the walls, actively watching for threats.
Anomaly detection
An AI security platform can act as a vigilant guard, analyzing incoming API calls and data inputs in real-time. It learns what “normal” inputs look like and can instantly flag or block requests that bear the statistical fingerprints of an adversarial attack.
Model behavior monitoring
These solutions continuously watch the AI’s predictions and, crucially, its confidence level scores. An attack might not always change the final prediction but may cause the model’s confidence to plummet. A sudden drop or a pattern of strange outputs can trigger an alert, signaling an attack in progress and initiating an incident response.
Techniques in AI Model Protection
Diving deeper than strategy, let’s look at the specific tactics and technologies that bring these layers of defense to life.
Adversarial example detection and defense
Adversarial examples are the ammunition of evasion attacks. Defense begins with detecting them. Input validation layers can check if incoming data conforms to expected distributions. More advanced anomaly detection systems use statistical methods or even secondary machine learning models to “sniff out” inputs that are likely adversarial. The primary defense remains adversarial training, where the model’s knowledge is expanded to include these threats, hardening it from within.
Model robustness enhancement
Beyond training on bad data, we can build models that are structurally more robust, through techniques like the ones below.
Regularization
Techniques like L1 and L2 regularization discourage overly complex models that might overfit to the training data, which often creates sharp, exploitable decision boundaries.
Gradient masking & defensive distillation
These advanced techniques aim to make it harder for an attacker to succeed. Gradient masking attempts to hide the gradient information that attackers use to craft their examples. Defensive distillation involves training a smaller “student” model on the smoothed-out probability outputs of a larger “teacher” model, resulting in a more resilient final product.
Secure model deployment
A robust model is useless if it’s deployed in an insecure environment.
Secure APIs and access controls
Implementing strong authentication, rate limiting, and access controls for model APIs can prevent model theft attacks and limit an attacker’s ability to probe the model for weaknesses.
- Model watermarking: This involves embedding a unique, secret signature into the model’s predictions. If a stolen model appears online, the owner can prove ownership by triggering the watermark, providing a powerful deterrent against theft.
- Regular updates and patching: Just like any software, the frameworks and libraries used to build and serve AI models (like TensorFlow or PyTorch) have vulnerabilities that must be patched regularly.
Monitoring, auditing, and response
Real-time monitoring provides the data needed for effective security governance. Having a detailed, immutable audit trail of all model inputs, prompts, and outputs is essential for forensic analysis after an incident. This data feeds into an incident response process: a pre-defined plan for what to do when an attack is detected. That plan may involve taking the model offline, switching to a safe mode, or alerting security personnel.
Trends and Emerging Solutions
The cat-and-mouse game between AI attackers and defenders is accelerating. Key emerging trends include the following.
AI-enabled security for AI models
Using specialized AI systems to monitor and protect other AI systems is becoming the new standard. These “guardian AIs” can learn to detect novel threats much faster than human-programmed rules.
Federated learning
This approach trains a global model on decentralized data (e.g., on individual mobile phones) without the raw data ever leaving the device. This provides strong privacy protections against data poisoning and theft at the source.
Zero-trust AI architectures
The “zero-trust” principle (never trust, always verify) can be applied to AI as well as traditional cybersecurity. Every API call, every data input, and every prediction is treated as potentially hostile and must be authenticated and validated before being processed.
Best Practices
For organizations deploying AI, some concise, actionable best practices for AI security include:
- Treating AI security as a lifecycle problem: Embed security checks at every stage, from data acquisition and model training to deployment and monitoring.
- Establishing a robust governance framework: Define who is responsible for AI security, what the acceptable risks are, and how you will comply with regulations.
- Prioritize data integrity: Your model is only as good as your data. Invest in tools for data validation, provenance tracking, and poisoning detection.
- Implement defense-in-depth: Combine data security, model hardening techniques, and real-time monitoring. Do not rely on a single solution.
- Maintain a human-in-the-loop: For high-stakes applications (like medical or financial decisions), ensure a human expert can review and override the AI’s decision, especially for low-confidence or anomalous outputs.
- Invest in specialized AI security tools: Recognize that traditional cybersecurity is not enough. Adopt platforms specifically designed to monitor, manage, and protect AI models.
Take Control of Your AI Risk with Lumenova AI
AI models are powerful but fragile. They face real, potent threats like data poisoning, evasion attacks, and model theft that can undermine their functionality and trustworthiness. As we’ve seen, defending against these threats requires a sophisticated, layered security approach that combines pristine data, hardened models, and vigilant, real-time monitoring.
AI security is not a one-time setup; it is an ongoing, dynamic process. As artificial intelligence becomes more deeply woven into the fabric of our economy and society, embedding security into every stage of the AI lifecycle is the only way to build lasting trust and ensure these transformative systems are used safely, responsibly, and effectively. The future of AI is thrilling, but it must be a secure one.
Navigating the complexities of AI security can be daunting. That’s why we built Lumenova AI, the all-in-one platform for AI model risk management, designed to implement the very principles discussed in this article. We help organizations secure the entire AI spectrum, from traditional ML deployment to safe, compliant, and transparent GenAI operations.
With Lumenova AI, you can:
- Ensure responsible AI behavior by monitoring all generated content for bias, toxicity, hallucinations, and the leakage of sensitive information.
- Achieve complete transparency with a comprehensive audit trail that logs every prompt, output, and user interaction with your models.
- Implement custom guardrails to steer AI behavior, ensuring all interactions align with your organization’s governance standards.
- Empower your experts with intuitive human-in-the-loop workflows, giving them final authority on high-stakes decisions.
- Streamline your compliance efforts with automated documentation, making it simple to demonstrate adherence to regulatory requirements.
Request a personalized demo today and see how Lumenova AI can help your company build a secure and trustworthy AI future!